A Student's Guide to Software Engineering Tools & Techniques »
Introduction to Machine Learning (ML)
Authors: Alex Fong
What is Machine Learning?
Machine learning is a subfield in artificial intelligence whereby computers learn from data to perform a task. Machine learning is powerful because it can discern complex patterns within data, and utilize them to produce desired outputs.
An example of a task is machine translation, where text is converted from one language to another by a computer. It is difficult to perform machine translation with regular programming, where we have to write clear instructions for the computer. ML alogirthms can be used instead to approximate the ideal instructions with data. In fact, ML algorithms have achieved state of the art performance for machine translation, as seen from the following blogpost on Google's machine translation algorithm.
The ML algorithms are fed with data to approximate the ideal instructions for performing tasks. These approximations are never 100% correct and there are various parameters to tweak for maximizing performance. Statistical analysis is used to evaluate the performance of different ML algorithm configurations.
Types of Machine Learning Tasks
Machine learning algorithms perform well for a large variety of tasks, from computer vision to natural language processing. Here is a non-exhaustive list:
- Sentiment analysis (NLTK example on Kaggle)
- Machine translation (NMT, by Google)
- Image generation (SuperRes, Texture Synthesis)
- Voice recognition, generation (DeepSpeech)
- Noise suppression (RNNoise)
- Optical Character Recognition (Tesseract-OCR)
- Data analytics (identifying trends, predicting sales)
- Recommender systems (recommending products based on user profiles)
- Instance segmentation (object detection & recognition to the pixel level MaskRCNN)
- Classification (often used for document indexing and retrieval)
Different algorithms and ML pipelines exist for performing the above tasks.
Types of Machine Learning Algorithms
There are two broad categories of ML algorithms, supervised learning and unsupervised learning.
Supervised Learning
In supervised learning, the data used for training is accompanied with desired outputs for the task. For the case of machine translation, an example input is a sentence in the source language. The desired output is the corresponding sentence in the target language.
Learning is 'supervised' as the algorithm is told whether it has made a correct prediction. Consequently, all training data must be labelled, and the labelling process may be costly. Platforms like Amazon Mechanical Turk are used for manual labelling of data.
One simple use case is image classification, to match the input image to a known label.

(samples from cifar10 dataset)
Unsupervised Learning
Unsupervised learning algorithms do not require labels.
Using clustering as an example, the data is split into groups by the algorithm. The downside is that it is difficult to explain the relationships between items grouped.
This approach can be used by e-commerce sites to identify similar products, where a clear and interpretable label for similar products is not required.

(T-SNE of Products Shape and Colour by Eddie Bell)
The following are popular resources for ML algorithms:
- Machine Learning: Stanford CS229
- Convolutional Neural Networks for Visual Recognition: Stanford CS231n
- Natural Language Processing with Deep Learning: Stanford CS224n
- A Practical Approach Towards Neural Networks: University of San Francisco, FastAI
Neural networks and Deep Learning are classes of ML algorithms.
They both contain supervised and unsupervised algorithms.
Note that there is one other category of ML algorithms, called reinforcement learning. Reinforcement learning is different from the above mentioned categories and will not be discussed in this introductory piece. More information on Reinforcement Learning can be found in this article (from Medium).
Types of Data
Data is broadly split into 2 categories, structured and unstructured.
Structured data refers to data in a standardized format with categories and values. Structured data is formatted like data in relational databases. A good example would be sales records, with fields like date, quantity sold, location and such.
Unstructured data refers to data without a predefined structure, such as images, audio and textual data.
The distinction between the types of data is important as ML algorithms are not always compatible with both data types. For example, Decision trees cannot be used for unstructured data. Data must be modified to a structured form for use with decision tree related algorithms.
How is Machine Learning Applied?
Bringing a machine learning algorithm to production requires a workflow which differs greatly from that of software engineering. This is due to a focus on prototyping.
Prototyping is required as ML algorithms vary in efficacy when used in different domains, each domain containing data of a different nature.
The algorithms contain various parameters that can be tuned to improve efficacy. Experimentation is required to discover the algorithm and parameters which give the best performance.
A machine learning algorithm is referred to as a model, after it is fed with data.
The entire prototyping process is similar to scientific experiments, where many model configurations are experimented on. Practitioners come up with a hypothesis on whether a configuration may improve performance, and verify if performance is as expected.
Prototyping Platforms and Tools
The prototyping phase in ML is usually done on Jupyter notebooks, or RStudio. The highlight of programming languages like Python and R, and the accompanying software is their strong support for experimentation and visualization of results.
Interpreted languages such as Python and R speed up prototyping iterations as they are less verbose than compiled languages like Java or C. Visualizations such as bar charts, graphs or just displaying the data assist in analysis and sharing of findings.
Code style, clarity and maintainability are less of a priority at this stage. A good example of Juptyer notebooks in action can be found at this page (from Kaggle).
Prototyping Workflow
Prototyping can be broken down into the following phases:
- Basic data preprocessing
- Partitioning of data
- Model training, evaluation and data analysis
- Repeating step 3
Basic Data Preprocessing
The quantity, quality and type of data differs greatly across domains, sometimes containing errors such as corruption or mislabelling. Basic data preprocessing is required to remove such data.
Other areas of concern are class imbalance (for supervised learning), where there are more data points in one class as compared to another. The data is modified in various ways to tackle class imbalance. This paper details various techinques for tackling class imbalance.
Partitioning of Data
Data is usually split into 3 sets after preprocessing: the test set, validation set and training set.
The FastAI ML MOOC1 is a great source of information on data partitioning.
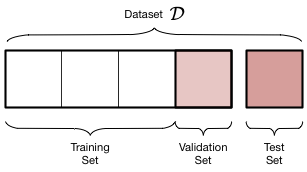
(Data partitioning visualization by David Zigano)
Test Set
ML algorithms are never 100% accurate. Testing ML algorithms on real world data is essential for estimating their efficacy.
Furthermore, ML models run the risk of overfitting the data they were trained on. Overfitting is a modelling error which occurs when models learn patterns unique to a subset of data. A model which overfits training data performs well on training data but is unable to translate this performance to real world data. A thorough explanation of overfitting can be found in this article (from EliteDataScience).
A test set solves the overfitting problem. A test set which resembles real world data as much as possible is created by partitioning the available data. Its size is dependent on the data available. The test set is used only for testing model performance, and will not be touched during model training.
Different schemes for partitioning must be used for data with different characteristics. More information on splitting test and validation sets (discussed next) can be found in this article (from FastAI).
Validation Set
A validation set is created from the remaining data in a similar fashion as the test set. The validation set is used to evaluate the performance of adjusting a model's parameters. Adjusting model parameters and verifying performance is conducted on the validation set to prevent overfitting the test set.
Guidelines on picking a size for the validation set can be found in Lesson 7 of FastAI's ML MOOC1.
The following driving factors are suggested for deciding the validation set size.
Business Concerns
Business concerns determine the significance of mistakes in predictions. For example, 4 mistakes in fraud detection is a much bigger issue than 4 mistakes in cucumber classification. A large enough validation set tells us if the difference in performance between 2 models is significant enough for the given problem.Statistical Stability
Each class should have at least 22 data points, so that the validation set follows an approximate normal distribution. This allows easier statistical analysis.
Training Set
The remaining data forms the training set.
Data in the training set is used for training the model.
Practitioners may choose to create a sample set from the training set, with a much smaller amount of data. This allows for quicker testing and refinement iterations. Training on the training set happens after a good set of algorithm parameters is found. This action is justified for Deep Learning and possibly other types ML algorithms, as seen in recent research.
Model Training, Evaluation, Data Analysis
Models are evaluated on the validation set after training on the training set. Practitioners perform data analysis on the results to gain insights on the data. These insights guide the practitioner in tweaking the data and model for better performance.
An example of data analysis for convolutional neural networks (an emerging class of ML algorithms) is to observe what the neural network is looking at when it makes its predictions. This can be done with class activation maps. After which, the practitioner may choose to perform further data preprocessing to help the neural network focus on the right areas.
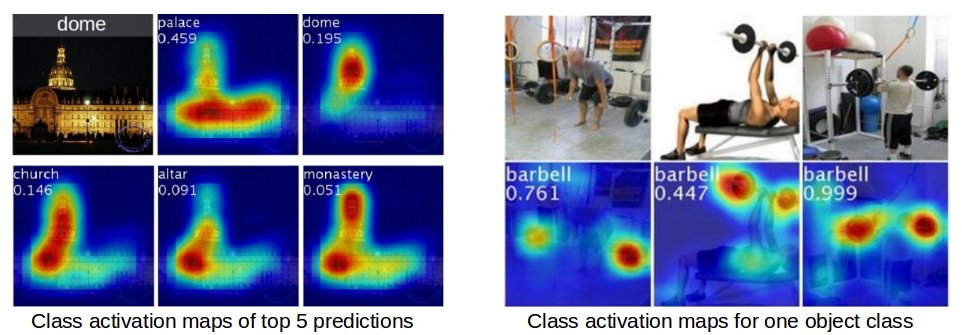
(Class activation maps, more information at http://cnnlocalization.csail.mit.edu)
Tweaking parameters and retraining the algorithm continues until the practitioner is satisfied with a particular model's performance. The model's score on the test set is used for selecting between different algorithms at the production stage.
Production
The best algorithm discovered is rewritten for production. They are usually rewritten in performance focused languages like C++, or in lower level ML frameworks such as Tensorflow.
Models are retrained on a regular basis when more data is available, allowing the model to learn new patterns from the data.
Techniques such as model compression must also be used to ensure that the models are within the desired size limit and perform fast enough. This paper contains a survey of existing compression techniques for neural networks.
Models are often trained against adversarial attacks for security reasons. An article detailing adversarial attacks on Deep Learning algorithms can be found in this article (from OpenAI).
Here are some articles and videos detailing the process of deploying ML algorithms for production.
Dropbox: OCR and automatic document rotation
Mozilla: DeepSpeech for voice recognition
PyData: Youtube Channel
Concluding Remarks
The process of coding a ML algorithm for production is an process fairly different from regular software development.
This chapter covers only the process of bringing a ML algorithm from prototyping to production, with little mention of specific algorithms. The process is mostly similar for all ML algorithms, from classical to emerging algorithms from Deep Learning.
Supplementary Resources
Commonly used libraries for machine learning
- General Machine Learning
- Numpy, provides support for large, multi-dimensional arrays, matrices & mathematical functions for operating these data structures
- Pandas, data analysis tool in Python
- Scikit-Learn, contains a big variety of machine learning algorithms (excluding Deep Learning)
- Deep Learning
- TensorFlow, library for Deep Learning by Google
- Stanford CS20: Tensorflow for Deep Learning Research, up to date best practices for Tensorflow
- Pytorch, by Facebook
Popular resources for keeping up with machine learning research
- https://arxiv.org/ (repository of electronic preprints of scientific papers)
- https://www.arxiv-sanity.com (provides a better browsing experience than Arxiv)
- https://openreview.net/ (peer reviews of research papers submitted to conferences)
Footnotes
[1]: No link is provided as MOOC is in unofficial release at time of writing