A Student's Guide to Software Engineering Tools & Techniques »
Introduction to Natural Language Processing (NLP)
Authors: Lum Ka Fai Jeffry
What is NLP?
Natural Language Processing (NLP) is the set of methods for making human language accessible to computers. Recent advances in NLP have given rise to useful tools that have become embedded in our daily lives, for example: spam and phishing classification keeps inboxes sane1; automated chatbots lighten the load on customer support staff and provide customers with immediate feedback2; machine translation bridge the gap between cultures3.
NLP draws from many other fields of science, from formal linguistics to statistics. The goal of NLP is to provide new computational capabilities around human language: for example, holding a conversation, summarizing an article, and so on.
Even though the study of NLP covers a diverse range of tasks, most of them can be generalized to three themes: syntax, semantics and relations.
Themes in NLP
Syntax
In order to transform language into a form understandable by computers, raw text must be converted to a general-purpose linguistic structure. In English, words can be decomposed to morphemes, the minimal unit of meaning (e.g. unhappiness to three morphemes un-happy-ness)4. Similarly, sentences can be tagged with word-level parts-of-speech which describe the meaning of each word in the context of that sentence.
 Figure 1. Parts of Speech
Figure 1. Parts of Speech
For example, 'informative' is tagged as an adjective (JJ) and 'article' as a noun (NN)5.
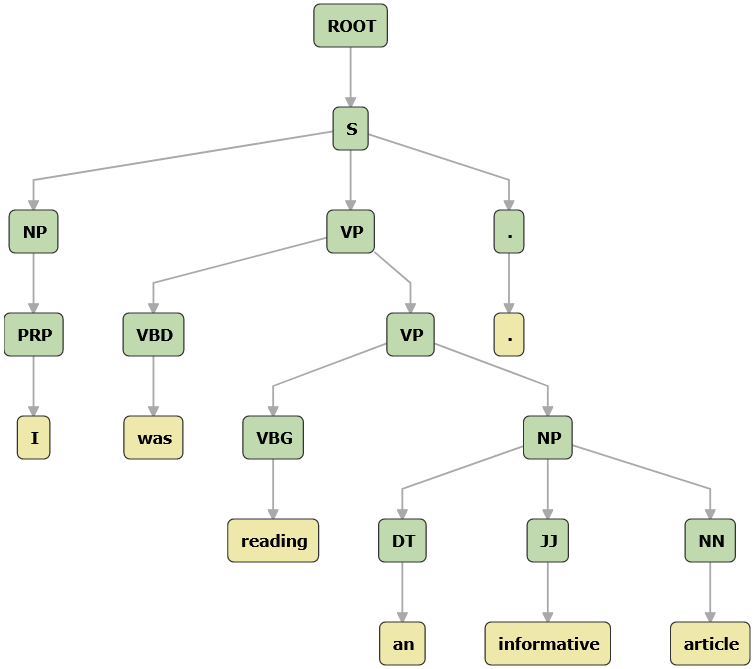 Figure 2. Constituency Parse
Figure 2. Constituency Parse
From the parts-of-speech tags, a tree-structured representation of grammar can be produced. This tree is the result of a a constituency parse is an assignment of a syntactic structure to a sentenceconstituency parse. From the tree we can see that the phrase 'an informative article' is simply a a noun phrase is a group of words that includes a noun and modifiers like adjectives.noun phrase. Incidentally, this is how Microsoft Word checks for grammatical errors6. Any tree that cannot be parsed may be grammatically incorrect or difficult to understand.
Semantics
With the knowledge of a sentence and its structure, the next step is to understand the meaning it conveys. To this end, the representation of the meaning of a sentence should be able to link language to concepts7.
Take for example the sentence:
I wrote an article!
In order to understand the meaning of the sentence, a few questions need to be answered:
- Who is 'I'?
- What is 'an article'?
- How are the two subjects related?
An approach is to represent the meaning of a sentence as a relationship triple consisting of a Subject, Object and Relation.
 Figure 3. Relation tuple
Figure 3. Relation tuple
From this representation of the sentence, it is possible for a system to answer novel questions like "Who has written articles?" or "What are the articles that 'I' have written". This technique, Open Information Extraction, is utilized by researchers to extract and summarize information from multiple documents.8
Relations
Relations are crucial to the understanding of natural languages. Consider the example:
Geoffrey bought Mary a ring. They have been dating for months.
What is the event that prompted Geoffrey to buy a ring? The word proposal, while not stated in the example, implicitly links the two events together. While humans are able to draw the connections instinctually, it is not easy to formalize this process computationally.
There are attempts to create semantic an ontology is a groupings of words by their meaningsontologies for natural language. WordNet is one such attempt, a handcrafted database that classifies words by concepts that they express9.
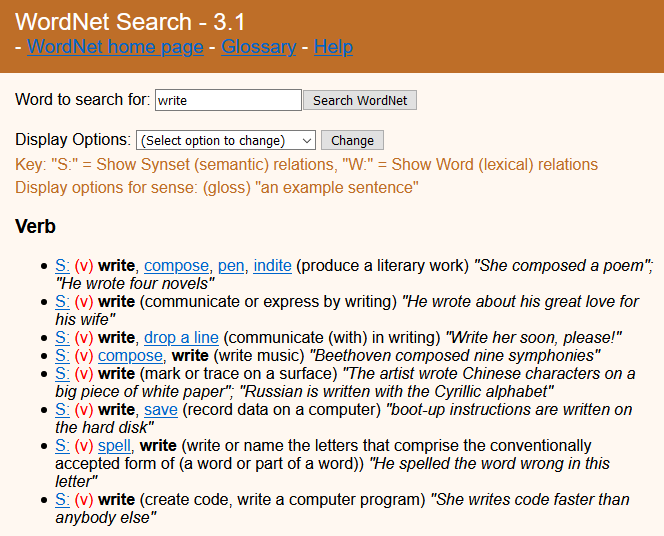 Figure 4. WordNet results for the word "write"
Figure 4. WordNet results for the word "write"
More recently, techniques like word2vec10 are able to model words and phrases as vectors of real numbers. This ability to quantify and categorize semantic similarity allows computers to infer beyond just synonyms.
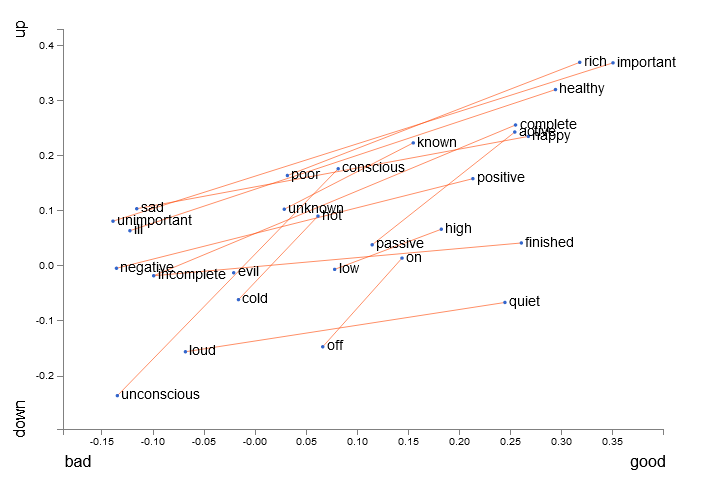 Figure 5. word2vec visualization for antonyms
Figure 5. word2vec visualization for antonyms
A simplified visualization of words in vector space shows that not only are words related in meaning close together, their antonyms are clustered together as well11. This implies that word vectors can be somewhat meaningfully combined by just using simple vector addition.
Word2vec has been used to analyze behaviour on e-commerce sites as human do not tend to browse for random items but purchase items that are related.
Applications of NLP
Input methods editors, e.g. Chinese, Japanese and Korean
Modern input method editors(IMEs) do more than simply translating input to output in the respective language. By tackling the syntactic and relational elements of natural language, IMEs provide autocomplete functionality by suggesting words that are related or occur together frequently.
For example, typing "beijing" in Moon IME, a Chinese IME, will bring up "olympics" as a possible suggestion12.
Indexing and information retrieval, e.g. Google's page rank and normalization of search terms
Search terms on Google are grouped together by semantic similarity in real time at volume to identify trends worldwide. This is achieved with techniques similar to word2vec.
Aggregation and clustering of documents, e.g. Cambridge Analytica, Google News
Techniques like doc2vec13 build upon word2vec and provide a representation of paragraphs in vector space. Similar to word2vec, this enables classification of documents and paves the road to powerful information retrieval techniques.
Machine translation, e.g. Google Translate
seq2seq3, a algorithm developed by Google, transforms a sequence to another. This family of techniques uses special an artifical neural networks is a computer system made up of a number of simple, highly connected processing elements which translate information to some form of desired outputartificial neural network architectures to model sentences.
Automated customer support, e.g. ChatBot, NanoRep
Human-curated databases (e.g. WordNet) are used together with techniques like word2vec to extract actionable words or phrases14. For example, the two possible input from users regarding a replacement for a digital banking token:
- I want to replace my token.
- My old token is broken.
can be mapped back to the same intent to which a predefined response can be given.
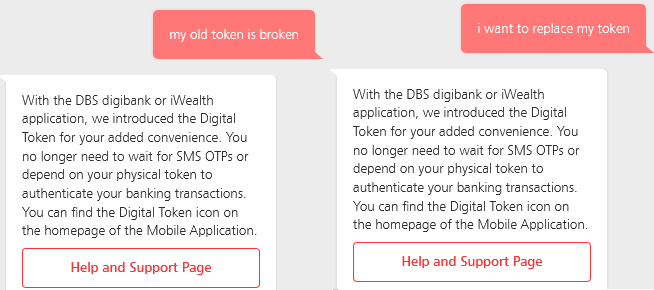 Figure 6. DBS chatbot responding to two different messages with a similar intent
Figure 6. DBS chatbot responding to two different messages with a similar intent
What's Next
Get an intuition for linguistics
The Language Instinct by Steven Pinker provides accessible insight about how humans learn language and the basics of formal linguistics. Learn about how to deconstruct language into formal structures for critical analysis through engaging examples.
Visually explore the themes present in NLP
Stanford's CoreNLP provides a visual representation of NLP techniques. Explore how sentences are annotated with parts-of-speech tags and see the output of a constituency parse.
Take an online course on NLP
Stanford University offers CS224n: Natural Language Processing with Deep Learning online. This course provides an introduction to modern techniques in NLP.
Experiment with NLP libraries
The aforementioned CoreNLP library is a good starting point for developers comfortable in Java. For a simple and productive experience, spaCy is a Python library suitable for experimentation and rapid prototyping.
References
[1]: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6562150/
[2]: https://azure.microsoft.com/en-us/services/bot-service/
[3]: https://github.com/google/seq2seq
[4]: https://www.cs.bham.ac.uk/~pjh/sem1a5/pt2/pt2_intro_morphology.html
[5]: https://catalog.ldc.upenn.edu/docs/LDC95T7/cl93.html
[6]: https://www.microsoft.com/en-us/research/project/nlpwin/
[7]: https://medium.com/huggingface/learning-meaning-in-natural-language-processing-the-semantics-mega-thread-9c0332dfe28e
[8]: https://www.aclweb.org/anthology/N13-1136
[9]: https://wordnet.princeton.edu/
[10]: https://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf
[11]: https://lamyiowce.github.io/word2viz/
[12]: https://www.aclweb.org/anthology/P18-4024.pdf
[13]: https://cs.stanford.edu/~quocle/paragraph_vector.pdf
[14]: https://www.microsoft.com/en-us/research/wp-content/uploads/2016/09/intent-detection-semantically.pdf